
xpath는 웹 크롤링을 효과적으로 하기 위한 도구로, html 문서에서 특정 요소를 찾기 위해 사용됩니다. 웹 크롤링을 통해 우리는 검색 엔진 크롤러가 어떻게 웹 사이트를 이해하고 색인하는지 파악할 수 있는데요. 따라서 웹 크롤링은 SEO (검색엔진 최적화)의 기초 작업 중 하나입니다.
이번 글에서는 xpath의 뜻과 문법, xpath로 웹 크롤링하는 방법을 알려드리겠습니다.
목차
- xpath란?
- html이란?
- xpath의 문법 : 절대경로와 상대경로
- 웹 크롤링에서 xpath의 중요성
- xpath를 활용한 웹 크롤링 예시
xpath란?
xpath란 ‘XML Path Language’의 줄임말로, XML이나 html 문서에서 특정 요소를 찾기 위한 경로를 지정하는 데 사용되는 언어입니다. xpath는 html로 짜인 웹 페이지에서 특정한 데이터를 가져오기 위해 해당 데이터가 포함된 html 요소를 지정하는데 유용한 도구입니다.
우리가 사용하는 웹페이지는 보통 html로 구성되어 있습니다. html 코드는 트리 구조로 이루어져 있기 때문에, 원하는 정보를 한 번에 빠르게 찾는 것이 어렵습니다. 예를 들어 특정 웹페이지에 삽입된 이미지의 대체 텍스트에 관한 정보를 찾고 싶거나, 헤딩 태그가 어떻게 작성되어 있는지 등의 정보를 찾고자 할 때 xpath를 사용하면 빠르고 정확하게 정보를 찾을 수 있습니다.
html이란?
xpath를 이해하기 전, html에 대해 먼저 알아보겠습니다. html이란 웹 페이지의 구조를 정의하는 언어입니다. html은 트리 구조라고 말씀드렸는데요. 트리 구조는 html문서가 마치 나무처럼 계층적으로 구성되기 때문에 생긴 이름입니다. 따라서 html의 구조를 이해하면 각 요소가 어떤 관계인지 파악할 수 있습니다.
html 트리 구조
<html>
<head>
<title>Example Page</title>
</head>
<body>
<h1>Welcome</h1>
<p>This is a paragraph.</p>
</body>
</html>
다음과 같은 html 문서가 있다고 가정해 보겠습니다. 이 트리 구조는 다음과 같이 표현할 수 있습니다.
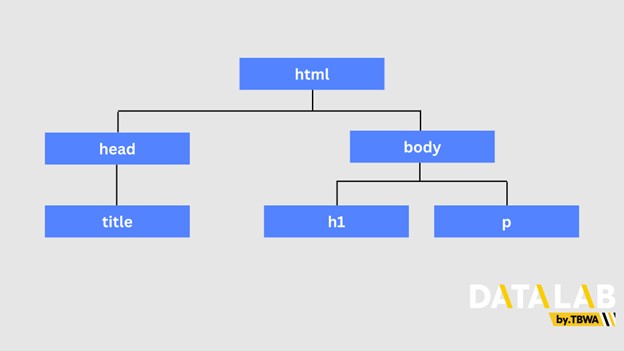
| 종류 | 요소 | 설명 |
|---|---|---|
| 루트 | html | 트리의 가장 최상위 요소 |
| 부모 노드 | head, body | 특정 요소를 포함하는 상위 요소 |
| 자식 노드 | title, h1, p | 부모 노드안에 포함된 하위 요소 |
| 형제 노드 | h1과 p | 같은 부모 노드를 공유하는 요소 |
html의 구성
html은 ‘태그(tag)’로 구성되어 있으며, 각 태그는 ‘요소(element)’를 감싸고 있습니다. 요소 안에는 추가적인 정보를 제공하는 ‘속성(attribute)’이 포함됩니다.
요소란, 태그와 그 안의 내용(텍스트, 다른 태그 등)으로 구성된 html의 기본 단위를 의미합니다. 요소는 <h1>제목</h1>의 형태로 이루어집니다.
태그란 html 문서의 특정 내용을 정의하는 기호로, 요소의 시작과 끝을 나타냅니다. <h1>, <div>, <span>,<p>등이 태그에 해당합니다.
속성이란 태그에 추가적인 정보를 제공하는 것으로, 속성=”값”형태로 작성됩니다. 속성은 시작 태그 내부에 작성합니다. <img src=”image.jpg” alt=”이미지 설명”>, <div id=”header” class=”main-header”> 와 같이 태그에 대한 부연 설명을 제공합니다.
html의 구성 요소를 예시와 함께 살펴보겠습니다.

| 구분 | 정의 | 예시 |
|---|---|---|
| 요소 (Element) | 태그와 그 안의 내용(텍스트, 다른 태그 등)으로 구성 | <p class=”nice”>Hello world!</p> |
| 시작 태그 (Opening Tag) | html 요소의 시작을 의미. 태그 이름과 속성을 의미함 | <p> |
| 종료 태그 (Closing Tag) | html 요소의 끝을 의미. 태그 앞에 /가 붙는 형식 | </p> |
| 속성, 값 (Attribute, Value) | 시작 태그 내 속성(class)과 해당 속성의 값(nice)을 정의 | class=”nice” |
| 텍스트 (Context) | 사용자에게 보이는 실제 텍 | Hello World! |
html 태그의 종류
마지막으로, html 태그의 종류에 대해 알아보겠습니다. 예시로 작성된 html 문서의 태그별 의미는 다음과 같습니다.
<html>
<head>
<title>예제 페이지</title>
</head>
<body>
<h1>안녕하세요!</h1>
<p>이것은 간단한 웹 페이지 예제입니다.</p>
<div class=”product”>
<h2>제품 정보</h2>
<span class=”price”>$10</span>
</div>
</body>
</html>
<html>: 문서의 루트 요소
<head>: 메타데이터 및 페이지 제목을 포함
<body>: 웹 페이지의 주요 콘텐츠가 들어가는 부분
<h1>, <h2>: 콘텐츠의 소제목을 구분해 주는 헤딩 태그
<p>: 단락을 의미하는 태그
<div>: 특정 콘텐츠를 그룹화하는 블록 요소
<span>: 주로 특정 텍스트에 스타일을 적용하거나 구조화된 데이터를 표시할 때 사용
xpath의 문법 : 절대경로와 상대경로
xpath로 특정 요소를 지정하는 방법은 2가지입니다. 절대경로(/) 또는 상대경로(//)로 특정 요소를 지정할 수 있습니다. 절대경로는 요소의 정확한 위치를 따라가고, 상대경로는 문서 내에서 조건에 맞는 모든 요소를 쉽게 선택할 수 있다는 장점이 있습니다.
정확한 이해를 위해, 하단의 사례를 예시로 절대경로와 상대경로를 비교해 보겠습니다.
<html>
<head>
<title>예제 페이지</title>
</head>
<body>
<header>
<h1>사이트 헤더 제목</h1>
</header>
<p>이것은 간단한 웹 페이지 예제입니다.</p>
<div class=”product” id=”item”>
<h1>제품 정보</h1>
<h2>제품 세부 정보</h2>
<span class=”price”>$10</span>
</div>
</body>
</html>
1) 절대경로
절대경로는 문서의 최상단 요소(루트)부터 시작해서 원하는 요소까지의 경로를 정확하게 명시하는 방법입니다. 절대경로를 사용하면 html 트리 구조의 시작점부터 순차적으로 모든 경로를 따라 내려가며 요소를 표시해야 합니다. 절대경로는 항상 /로 시작합니다.
위의 사례에서 절대경로를 이용하여 첫 번째 <h1>인 ‘사이트 헤드 제목’을 찾고 싶다고 가정해 보겠습니다. 절대경로는 루트인 html에서 시작해 하단의 body를 지나 header, 그리고 더 하단의 h1으로 내려가야 합니다. 따라서 절대경로를 사용하여 <h1>요소를 찾는 값은 /html/body/header/h1입니다. 이 xpath를 사용하면 “사이트 헤드 제목”이 포함된 h1 요소를 찾을 수 있습니다.
만약 두 번째 <h1>을 찾고 싶다면, 두 번째 h1요소는 div 요소 안에 포함되어 있기 때문에, 절대경로는 /html/body/div/h1이 되어야 합니다. 이 xpath는 “제품 정보” h1을 찾아냅니다.
절대경로는 특정 요소에 도달하기 위한 경로가 명확하게 설정되어 있기 때문에, 구조가 고정된 문서에서는 정확하게 요소를 찾아낼 수 있다는 장점이 있습니다. 그러나 문서에 따라 경로가 길어질 수 있으며, 문서 구조가 변경되면 xpath도 수정이 필요하다는 단점이 있습니다.
2) 상대경로
상대경로는 특정 요소를 기준으로 그 주변의 데이터를 찾는 방법입니다. 상대경로는 //로 시작하며, 문서 내의 모든 위치에서 해당 요소를 찾아냅니다.
상대경로를 이용해 h1태그를 찾고 싶다면 //h1 을 사용하면 됩니다. 이 경우, 문서 내의 모든 h1을 찾아냅니다. 따라서 결과값으로는 “사이트 헤더 제목”과 “제품 정보” 모두를 찾아낼 수 있습니다.
상대경로를 이용해서 특정 요소의 속성을 찾아낼 수도 있습니다. xpath에서 @는 특정 요소의 속성(ex. class, id, href, src 등)을 참조하는 것을 의미합니다. 예를 들어, 위의 사례에서 id 속성을 가지고 있는 div요소를 선택하고 싶다면 //div[@id=”item”]를 사용하면 됩니다.
상대경로는 간단한 경로로 요소를 찾을 수 있으며, 특정 클래스나 ID, 태그 등을 기준으로 요소를 선택할 수 있기 때문에 비교적 쉽게 사용할 수 있습니다. 그러나 경로가 유연하게 사용되는 만큼 한 번에 내가 원하는 정확한 요소를 찾기 어려울 수 있습니다.
3) 기타 연산자 및 조건문
xpath를 지정할 때, 특정 요소를 지정하는 조건문을 사용할 수 있습니다.
<html>
<body>
<div class=”item”>첫 번째 항목</div>
<div class=”item highlight”>두 번째 항목</div>
<div class=”item”>세 번째 항목</div>
<div class=”item”>네 번째 항목</div>
<div class=”item special”>다섯 번째 항목</div>
</body>
</html>
contains
contains는 특정 값과 일치하는 요소를 찾을 때 사용합니다. 예를 들어, class 중 ‘item’이라는 단어가 포함되는 모든 div 요소를 찾고 싶다고 가정해 보겠습니다. 이런 경우 contains 구문을 사용하여 원하는 값을 찾을 수 있습니다.
- 사용 xpath: //div[contains(@class, ‘item’)]
- 결과값: <div class=”item”>첫 번째 항목</div>, <div class=”item highlight”>두 번째 항목</div>, <div class=”item”>세 번째 항목</div>, <div class=”item”>네 번째 항목</div>, <div class=”item special”>다섯 번째 항목</div>
last
last는 여러 요소 중 마지막에 해당하는 요소를 선택할 때 사용합니다. class 중 item이라는 단어가 포함된 div 요소 중, 마지막에 해당하는 부분만 찾고 싶을 때 last 구문을 사용할 수 있습니다.
- 사용 xpath: //div[contains(@class, ‘item’)][last()]
- 결과값: <div class=”item special”>다섯 번째 항목</div>
text
text()는 요소 내의 텍스트 정보를 선택할 때 사용됩니다. text()를 활용하면 특정 텍스트를 포함하는 요소를 선택할 수 있습니다. 예를 들어, ‘두 번째 항목’이라는 텍스트가 포함된 부분을 찾고 싶다면 다음과 같은 text()구문을 사용하면 됩니다.
- 사용 xpath://div[text()=’두 번째 항목’]
- 결과값: <div class=”item highlight”>두 번째 항목</div>
and
and는 두 조건을 모두 만족하는 요소를 찾을 때 사용합니다. 예를 들어, class 중 item이라는 단어와 highlight라는 단어 모두를 포함하고 있는 요소만 선택하고자 한다면 and 구문을 활용해 다음과 같은 xpath를 사용할 수 있습니다.
- 사용 xpath: //div[contains(@class, ‘item’) and contains(@class, ‘highlight’)]
- 결과값: <div class=”item highlight”>두 번째 항목</div>
or
or는 두 조건 중 하나라도 만족하는 요소를 찾을 때 사용합니다.
- 사용 xpath: //div[contains(@class, ‘highlight’) or contains(@class, ‘special’)]
- 결과값: <div class=”item highlight”>두 번째 항목</div>, <div class=”item special”>다섯 번째 항목</div>
not
not()은 특정 조건을 제외한 값을 찾고 싶을 때 사용합니다. 전체 조건 중 제외하고 싶은 값을 not안에 포함해 작성합니다. 예를 들어 class 속성 중 special이 포함되지 않은 모든 div 요소를 찾고 싶을 때 다음과 같은 구문을 사용할 수 있습니다.
- 사용 xpath: //div[not(contains(@class, ‘special’))]
- 결과값: <div class=”item”>첫 번째 항목</div>, <div class=”item highlight”>두 번째 항목</div>, <div class=”item”>세 번째 항목</div>, <div class=”item”>네 번째 항목</div>
position
position은 요소의 위치를 기준으로 선택할 때 사용합니다. 예를 들어 클래스가 Item인 요소 중, 두 번째 위치에 있는 요소를 선택하고 싶다면 position 구문을 사용하여 찾을 수 있습니다.
- 사용 xpath: //div[@class=’item’][position()=2]
- 결과값: <div class=”item highlight”>두 번째 항목</div>
웹 크롤링에서 xpath의 중요성
웹 크롤링이란?
웹 크롤링이란 웹 페이지에서 데이터를 추출하는 작업을 의미합니다. 검색엔진은 웹 크롤러를 사용하여 웹 페이지를 탐색하고, 페이지 내 콘텐츠나 링크 구조 등을 분석하여 색인합니다. 이렇게 색인된 페이지들을 바탕으로 사용자가 검색어를 입력했을 때, 알고리즘을 적용하여 검색 결과 페이지(serp)를 사용자에게 보여주게 됩니다.
SEO의 목적은 검색엔진 상위 노출이기에, 검색엔진 크롤러가 어떻게 웹 사이트를 이해하고 탐색하는지를 파악하는 것은 웹사이트 최적화를 위한 필수 과정입니다. 따라서 SEO를 위해서는 웹 크롤링을 위한 xpath 지식이 필요합니다.
xpath로 얻을 수 있는 크롤링 관련 정보
xpath를 활용해 얻을 수 있는 대표적인 SEO 정보의 종류는 다음과 같습니다. 이 외에도 구조화된 데이터 여부, url 형식 등 다양한 정보를 확인할 수 있습니다.
1) 메타 태그
2) 헤딩 태그
- 헤딩 태그(<h1>, <h2>, 등): 페이지의 주요 제목과 소제목
3) 이미지
- 삽입된 이미지 링크(<img src=”…”>): 페이지에 삽입된 이미지의 URL
- ALT 속성 (<img alt=”…”>): 이미지에 대한 설명을 제공하는 대체 텍스트
4) 링크
- 내부 링크: 페이지 내의 다른 페이지로 연결되는 링크를 추적하여 사이트 구조와 사용자 흐름 분석
- 외부 링크: 외부 사이트로 연결되는 링크를 분석하여 신뢰성과 링크 빌딩 전략 평가
5) 콘텐츠
- 텍스트: 작성된 콘텐츠의 텍스트 추출 가능
- 콘텐츠 작성일 / 변경일: 페이지 및 게시물의 작성일 또는 마지막 수정일 확인
- 비디오 및 기타 미디어: (<video>, <iframe>) 등의 태그로 삽입된 비디오 콘텐츠의 링크 및 정보 확인
- 구문 강조 (<strong>, <em>): 중요한 키워드 강조 여부를 분석하여 SEO 최적화 상태 평가
xpath를 활용한 웹 크롤링 예시
xpath를 활용한 웹 크롤링 방법을 소개해 드리겠습니다.
- 검사하고 싶은 페이지에 들어가 마우스 오른쪽 버튼 클릭 > 검사 클릭하여 chrome 개발자 도구에 들어갑니다.

- 상단 바에서 ‘검색할 페이지 요소 선택’을 누른 뒤, 추출하고 싶은 부분에 커서를 갖다대 해당 부분의 html 코드를 확인합니다.
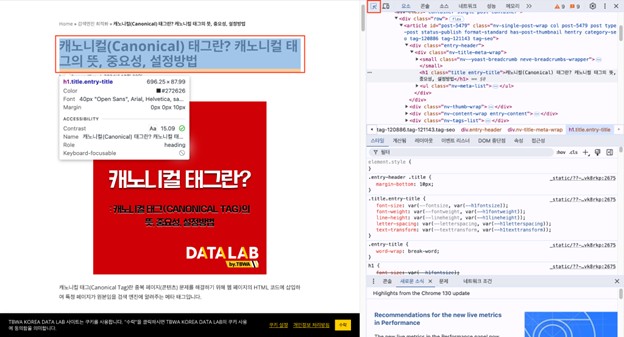
- 해당 부분을 복사한 뒤, 내가 원하는 내용을 추출하기 위한 xpath를 확인합니다. 예를 들어, 해당 페이지에서 <h1> 텍스트 내용을 추출하고 싶다고 가정해 보겠습니다.
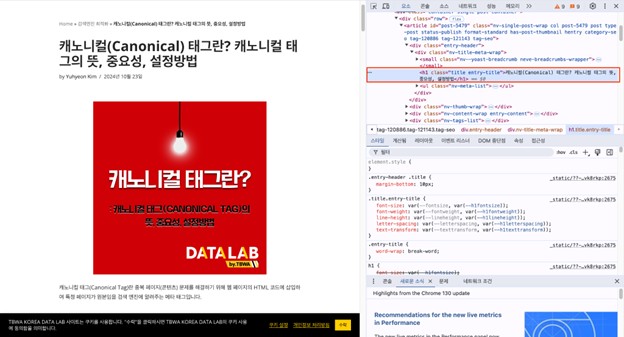
<h1 class=”title entry-title”>캐노니컬(Canonical) 태그란? 캐노니컬 태그의 뜻, 중요성, 설정방법</h1>
전체 h1은 위와 같습니다. 이 중 텍스트에 해당하는 부분만 추출하고 싶다면 //h1[@class=’title entry-title’]/text()를 사용하면 됩니다.
- 크롤링 도구에 xpath를 넣고 크롤링합니다. 여러 콘텐츠의 정보를 한 번에 추출하고 싶을 때 특히 사용하기 좋은 방법입니다. web scraper 확장 프로그램을 사용해 여러 개의 콘텐츠의 모든 h1태그를 한 번에 추출해 보겠습니다. 크롤링 도구는 web scraper 이외에도 screaming frog나 파이썬 등을 활용할 수 있습니다.
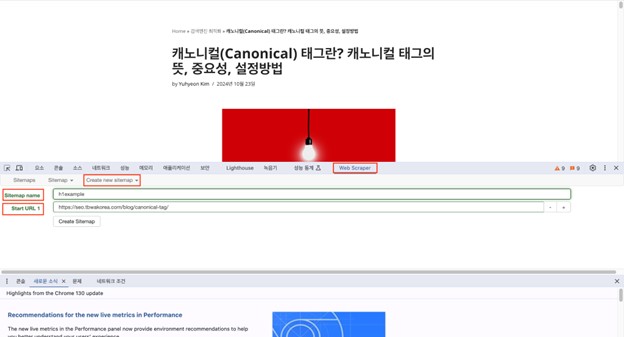
– web scraper 확장 프로그램 설치 후 create new sitemap 클릭
– sitemap name : 생성할 사이트맵 제목 설정
– site url : 크롤링할 사이트 주소 입력
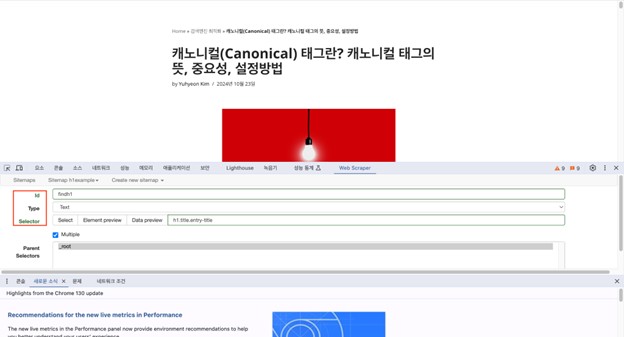
– add new sector 클릭 후 id, type, selector 선택
– id: 찾을 요소의 이름
– type: text, link, Image, table 등 다양한 요소 중 원하는 값 선택. h1 추출할 경우 text를 선택
– selector: 찾아 놓은 xpath를 입력. 만약 ‘Must be a valid CSS selector’ 값이 뜬 경우, 찾아 놓은 xpath를 css로 변환 필요. css 변환은 챗GPT를 이용하면 쉽게 변환 가능.
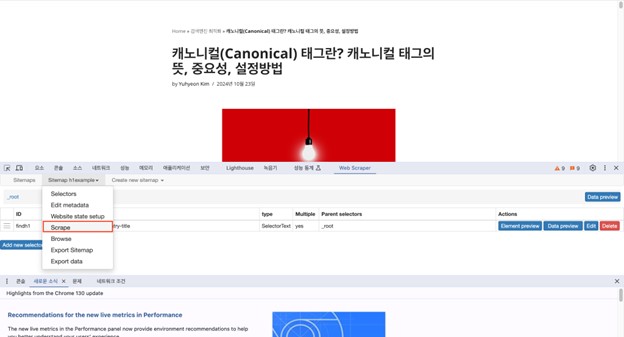
– 만들어 놓은 사이트맵 클릭 > scrape 시작
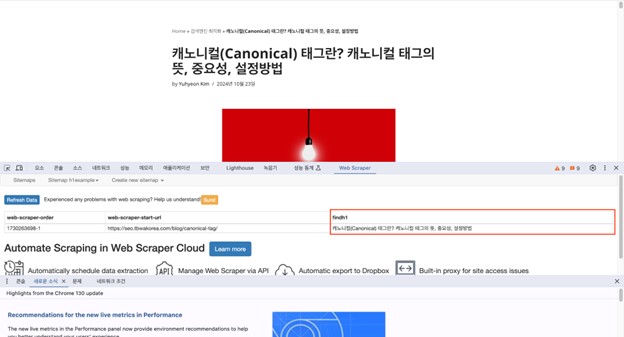
– 결과값 확인
이 외에도 xpath를 활용하면 내부/외부 링크, 메타 디스크립션 등 콘텐츠의 seo를 분석하는 데 도움이 되는 다양한 데이터를 추출할 수 있습니다. 콘텐츠 상위 노출이나 웹사이트 진단에 대해 궁금한 내용이 있으시다면 하단의 링크로 문의 남겨주세요.
>> TBWA DataLab 본문 바로가기
>> TBWA DataLab 컨설팅 서비스 바로가기
해당 글은 TBWA 데이터랩과 모비인사이드의 파트너쉽으로 제공되는 기사입니다.
![]()
")

