
제1편. 4차 산업혁명의 석유, 데이터를 다루는 역량에 대하여
– 빅데이터 시대 필수 역량인 ‘데이터 리터러시’ 파헤치기(1)
제2편. 방대한 양의 데이터를 한눈에 쉽게 보는 법이 궁금하다면?
– 빅데이터 시대 필수 역량인 ‘데이터 리터러시’ 파헤치기(2)
데이터 시각화란 무엇인가요?
“데이터 분석 결과를 쉽게 이해할 수 있도록 시각적으로 표현하고 전달되는 과정”
위키백과에서는 데이터 시각화를 위와 같이 정의하고 있습니다. 풀이가 조금 더 잘 와 닿을 수 있도록, 아래 예시를 보여드리겠습니다.

구글 애널리틱스의 획득 보고서 화면입니다. 우리 웹사이트에 들어온 유입자가 어떤 경로(채널)를 통해 들어왔는지를 나타내는 표입니다.
각 채널로 세션이 유입되는 수를 비교해보고, 평균 세션 시간이 궁금하여 측정항목을 확인해 보았습니다. 그런데 숫자가 많아한눈에 잘 들어오지 않을뿐더러, 다른 기준과의 비교도 어렵습니다.
이를 시각화해보면 다음과 같습니다.
![[그림 2] GA 획득 보고서의 전체 트래픽_ 트리맵](https://mobiinsidecontent.s3.ap-northeast-2.amazonaws.com/kr/wp-content/uploads/2019/06/03152234/20190603_152218.png)
기준이 되는 세션의 비율은 크기로 나타납니다. 반면, 평균 세션 시간은 색상으로 나타납니다.
크기가 가장 큰 Display 채널이 가장 많은 세션을 유입시킨 채널입니다. 하지만 해당 세션의 평균 세션 시간은 높지 않음을 알 수 있습니다. 색상이 가장 진한 Referral 채널을 통해 유입된 세션은, 세션 수는 적어도 가장 오랜 시간을 머물렀음을 한눈에 파악할 수 있습니다. 하나의 차트에서 두 가지 기준 항목을 확인할 수 있는 시각화 사례입니다.
이처럼 숫자로는 들어오지 않는 데이터를 한눈에 보기 쉽도록 정리하는 단계가 바로 데이터 시각화입니다.
어떤 차트를 어디에 사용할까요?_ 차트 종류 및 용도
데이터를 시각화하기 위해 사용하는 차트의 종류에는 어떤 것들이 있을까요?
아주 다양한 차트가 있지만, 대표적으로 많이 사용되는 아래 다섯 가지를 살펴보겠습니다.
・바 차트 (막대그래프)
두 가지 이상의 변수 간 데이터를 비교할 때 사용
・라인 차트 (꺾은선 그래프)
데이터의 트렌드 및 패턴을 파악하기에 용이
・분산 차트 (산포도)
두 변수 간 상관관계를 표현하기에 용이
・파이 차트 (원그래프)
전체 항목의 비율을 100으로 놓고 보았을 때, 각 항목이 전체에서 차지하는 비율을 비교하기에 유용
・방사형 차트
데이터 계열이 여러 가지일 때, 데이터 값을 비교하기에 유용

각각의 차트가 다르게 생긴 만큼, 쓰이는 상황도 다릅니다. 데이터를 시각화할 때에는 목적에 맞는 차트를 사용해야 합니다. 그래야 데이터의 패턴을 파악하고, 이슈를 확인하고, 해결방안을 도출할 수 있기 때문입니다.
데이터 시각화 유의사항
데이터를 시각화할 때 주의해야 하는 점이 있습니다. 바로 데이터의 왜곡이 없는지 확인해야 한다는 점입니다.
아래 두 그래프를 살펴보겠습니다. 둘 중 잘못된 차트는 무엇일까요?
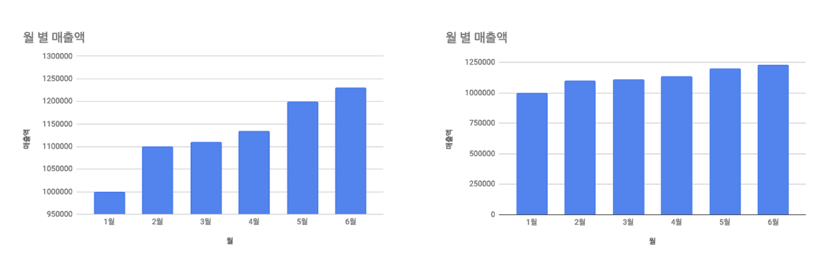
왼쪽 그래프의 Y축 시작 값을 먼저 보시겠습니다. 950,000원을 나타내고 있습니다.
반면, 오른쪽 그래프의 Y축 시작 값은 0원을 나타내고 있습니다.
두 그래프는 모두, 아래 하나의 데이터를 나타내는 그래프입니다.

데이터 시각화 유의사항 (2)
이처럼, 시각화를 하는 사람의 개인적인 의견이 반영된다면 해석의 왜곡을 일으킬 수 있습니다. 그래서 데이터를 시각화할 때에는 데이터의 왜곡이 없는지를 확인해야 합니다.
당연한 이야기를 한다고 생각하실 수 있습니다. 하지만, 실제로 우리가 자주 접하는 뉴스에서도 데이터 왜곡이 일어나는 경우가 빈번합니다.
사실을 전해야 하는 뉴스에서 데이터 왜곡이라니, 믿기 어려우시겠다고요? 그래서 실제 사례를 보여드리고자 합니다.
데이터 왜곡 실제 사례
먼저 SBS 뉴스 사례입니다.

중국에 수출하는 비중, 그리고 미국+EU+일본에 수출하는 비중을 비교해 놓은 차트입니다. 해당 사례에는 두 가지 왜곡이 존재합니다.
1) 그래프를 언뜻 보면, 중국에 수출하는 비중이 부각되어 큰 폭으로 높아 보입니다. 그러나 수치를 확인해 보면, 두 데이터의 차이는 0.4% p 뿐입니다. 시각화를 할 때 의도적으로 차이를 강조하여 부각함으로써 왜곡이 일어난 것으로, 잘못된 차트 활용의 예라고 할 수 있겠습니다.
2) 또 다른 왜곡은 변수 조작의 왜곡입니다. ‘한 국가에 수출하는 비중’이라는 통일된 기준이 아닌, ‘한 국가에 수출하는 비중(중국)’과 ‘두 국가와 연합체에 수출하는 비중을 모두 합친 비중(미국+EU+일본)’을 비교하고 있습니다. 변수를 임의적으로 조작하고 통합하는 의도적인 왜곡이 발생한 것입니다. 데이터의 비교는, 같은 수준의 단위로 이루어져야 합니다.
또 다른 사례를 보시겠습니다. JTBC 뉴스룸에서의 데이터 왜곡 사례입니다.
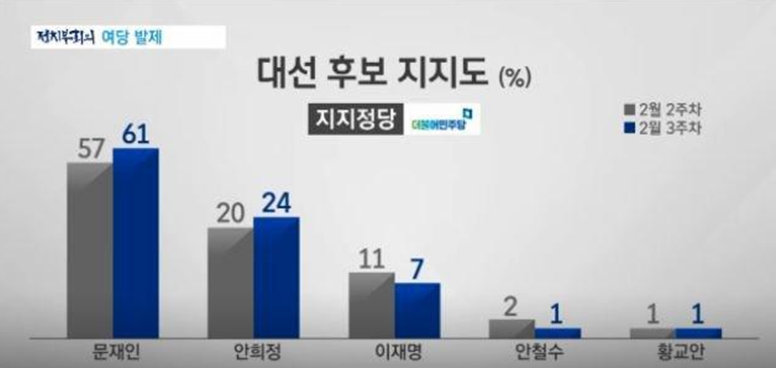
지난 대선 당시, 대선 후보 지지도를 보여주는 과정에서 JTBC는 지지율 24%인 안희정 후보의 막대그래프를 문재인 후보의 61% 막대그래프의 절반 이상의 높이로 나타냈습니다. 숫자보다 시각화에 더 빠르고 민감하게 반응하는 시청자들을 상대로 왜곡을 일으킨 것입니다.
이를 옳은 그래프로 나타내려면 다음과 같이 정정해야 합니다.

마찬가지로, 아래 그래프에서도 왜곡이 발생하고 있습니다. 역시 jtbc의 사례입니다.
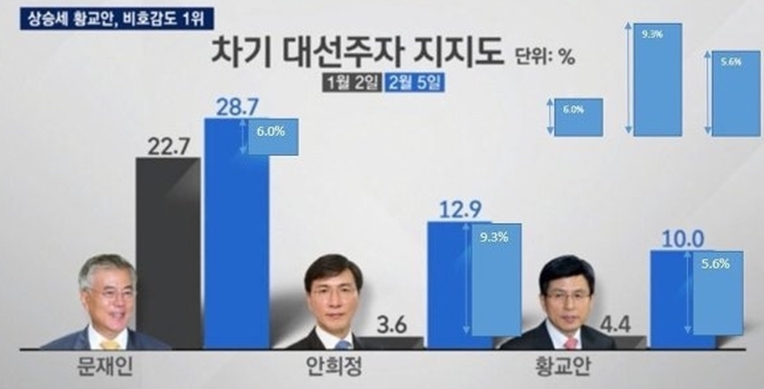
대선주자 지지도 상승폭 그래프에서 문재인 후보의 상승폭은 축소하고, 나머지 후보들의 상승폭을 과장하여 나타내기도 했습니다. 그림으로 나타낸 차이 폭을 보시면 황교안 후보의 상승폭 5.6%p가 문재인 후보의 상승폭인 6%p보다도 두 배 이상으로 크게 나타나 있음을 알 수 있습니다.
이를 옳은 그래프로 나타내려면 다음과 같이 정정해야 합니다.

결국 JTBC는 빈번한 그래프 오류와 오역 보도에 대해 사과하는 상황에 이르렀습니다. 어쩌면 의도적인 왜곡이었을지라도, 우리는 정확한 정보를 파악해야 합니다. 데이터 시각화 역량을 길러야 하는 이유입니다.
이런 차트도 있어요!
데이터 시각화와 관련해서, 흥미로운 차트 두 가지를 알려드리고자 합니다.
1) 단계 구분도 (Choropleth map)
이번 봄, 다들 미세먼지로 고생하셨죠? 신문 기사 또는 뉴스에서 아래와 같은 미세먼지 지도를 다들 한 번쯤 접해보셨을 듯합니다.

데이터 시각화 사례_ 서울 지역별 초미세먼지 나쁨 초과일수 (출처:국립환경과학원)
이런 종류의 차트를 ‘단계 구분도’라고 합니다. 지역 별 데이터를 서로 다른 색상이나 음영으로 지도 위에 표기하는 차트입니다.
차트를 보면, 2015-2018년도에는 마포구와 관악구가 초미세먼지 나쁨 단계를 초과하는 빈도가 가장 잦았다는 사실을 직관적으로 확인할 수 있습니다. 이처럼 지역 별 데이터를 한눈에 보기 쉽다는 장점 때문에, 지역 관련 통계에 빈번히 사용되는 차트 유형입니다.
2) 코드 다이어그램 (Chord diagram)
또 다른 흥미로운 차트입니다. 웹사이트 사용자 행동 분석 솔루션 빅인(bigin)의 대시보드 차트인데요. 생김새를 먼저 보여드리겠습니다.

이렇게 생긴 차트를 ‘코드 다이어그램’이라고 합니다. 변수 간의 연결관계를 표현하는 동시에, 각 변수 별 데이터를 직관적으로 확인할 수 있다는 장점이 있습니다.
웹사이트 이용자의 행동을 분석하여 상품 별 관련성을 찾아주는 빅인 솔루션의 경우, 코드 다이어그램 차트를 통해 기준이 되는 상품 (A 상품)과 관련 있는 상품들을 연결 짓고 시각화합니다.

드릴다운을 통해 계층을 이동해보겠습니다. ‘클릭해서 더 보기’를 클릭하여, A 상품과 관련 있는 상품들만 따로 모아볼 수 있습니다. 그리고 해당 상품을 구매할 가능성이 큰 잠재고객 목록을 조회할 수 있습니다.
데이터를 직관적으로 보여주기 위해 시각화하는 방안이 아주 다양하다는 사실을 말씀드리고자 (그리고 서비스 자랑도 살짝 얹고자) 빅인 솔루션의 사례를 보여드렸습니다.
데이터 시각화 자료를 볼 수 있는 사이트
끝으로 데이터를 시각화 한 자료를 볼 수 있는 사이트 두 곳을 알려드리겠습니다. 더 많은 사례와 차트의 쓰임이 궁금하신 분들은, 아래 사이트를 참고하시면 도움이 될 것입니다.
1) 공공데이터포털사이트
행정안전부에서 제공하는 서비스인 공공데이터포털사이트인데요. 국민이 쉽고 편하게 공공데이터를 이용할 수 있도록 한다는 취지의 사이트입니다. 메뉴바의 ‘활용사례’ 탭에서 ‘공공데이터 시각화 자료’를 보시면, 다양한 분야에 걸친 공공데이터 시각화 자료를 보실 수 있습니다.
2) 통계지리정보서비스
통계청에서 제공하는 통계지리정보서비스에서도, 국내 지역별 데이터를 확인할 수 있습니다. 인구, 주거, 복지 등의 정보를 지도 위에 나타낸 다양한 시각화 자료들을 찾아볼 수 있습니다.
글을 마치며
두 편의 글을 통해 데이터 리터러시 역량과, 그 하위 역량 중 하나인 데이터 시각화에 대해 알아보았습니다.
데이터 시각화는 공들여 수집하고 가공한 데이터에서 인사이트를 뽑아내기 위해 필수적인 단계입니다. 그리고 시각화된 데이터, 즉 차트나 그래프는 신문 기사/뉴스에서도 자주 볼 수 있을 만큼 우리 삶과 밀접하게 연관되어 있습니다. 데이터 분석가가 아니더라도 데이터 시각화 역량이 필요한 이유입니다.
다양한 차트의 유형을 파악해야 데이터를 오류 없이 해석할 수 있습니다.
여러 차트를 꾸준히 접해보아야 데이터 시각화를 통해 전달할 메시지가 무엇인지 명확하게 알 수 있습니다.
일상생활에서 차트를 접할 때에도 데이터의 왜곡은 없는지, 데이터를 나타낼 더 좋은 차트는 없을지 고민해보며 시각화 역량을 길러나가는 독자분들이 되시기를 저희 빅인사이트가 응원하겠습니다.
[fbcomments url=” https://www.mobiinside.com/kr/2019/06/03/big-data/” width=”100%” count=”off” num=”5″ countmsg=”wonderful comments!”]


