데이터 시각화는 우리 생각보다 더 자주 사용되고, 쉽게 볼 수 있습니다. 배달 음식을 주문할 때 확인한 별점이나 가게 리뷰를 키워드 형태로 보여주는 워드 클라우드 등도 데이터 시각화 유형 중 하나예요. 방송이나 신문에서 자주 볼 수 있는 각종 차트들도요. 모두 방대한 데이터를 이해하기 쉽도록 가공한 시각화입니다.
데이터 분석 결과를 쉽게 이해할 수 있도록 시각적으로 표현하는 데이터 시각화. 데이터를 시각화할 때 가장 중요한 점이 무엇이라고 생각하세요? 차트의 종류를 선택하는 것? 아니면 보기 좋은 디자인? 그냥 예쁘기만 하면 올바른 데이터 시각화일까요?

데이터를 시각화 하는 이유
심리학 용어 중에 ‘그림 우월성 효과’라는 게 있대요. 그림(이미지)이 단어보다 더 쉽게 인지되고 잘 기억나는 현상을 이야기하는데요, 우리가 데이터를 시각화하는 이유도 여기에 있어요. 데이터 분석 결과를 쉽게 이해할 수 있도록 시각적 요소로 정보를 전달하기 위해서 입니다.
다시 말해서, 데이터 시각화의 목적은 원활한 커뮤니케이션에 있다고 할 수 있습니다. 데이터가 가진 원래의 의미를 보다 쉽게 전달해야 데이터 시각화를 제대로 했다고 할 수 있습니다. 정보전달의 효율성을 고려하는 것은 물론이고요.
그렇다면, 우리는 데이터 시각화를 얼마나 잘하고 있을까요? 여러 기사와 콘텐츠 등을 보니 데이터 시각화를 많이 사용하는 만큼 이런저런 오류들을 발견할 수 있었어요. 그래서 탄생한 이번 콘텐츠의 주제! 데이터 시각화의 재구성입니다. 잘못된 시각화 사례들을 살펴보고 적합한 유형으로 바꾸어 볼 거예요. 시각화를 제작하는 사람에 따라 해석은 조금씩 달라질 수 있다는 사실을 기억해주시고 이 콘텐츠를 보는 여러분은 어떤 유형을 선택하고, 시각화 차트를 만들지 함께 생각해보면 어떨까요?
무작정 그리지 맙시다! – 막대차트
막대차트는 흔하게 볼 수 있는 데이터 시각화 유형 중 하나인데요, 지표를 항목별로 비교할 때 사용합니다. 항목별 지표 값을 절대적⋅상대적으로 정확하게 표현할 수 있으며 데이터의 크기에 따라 막대 길이를 달리해 값을 나타냅니다. 이때 축은 반드시 0부터 시작해야 합니다.(99%는 반드시, 1%는 데이터의 특성을 고려해 0이 아닌 경우도 있답니다. by. 강젤리)
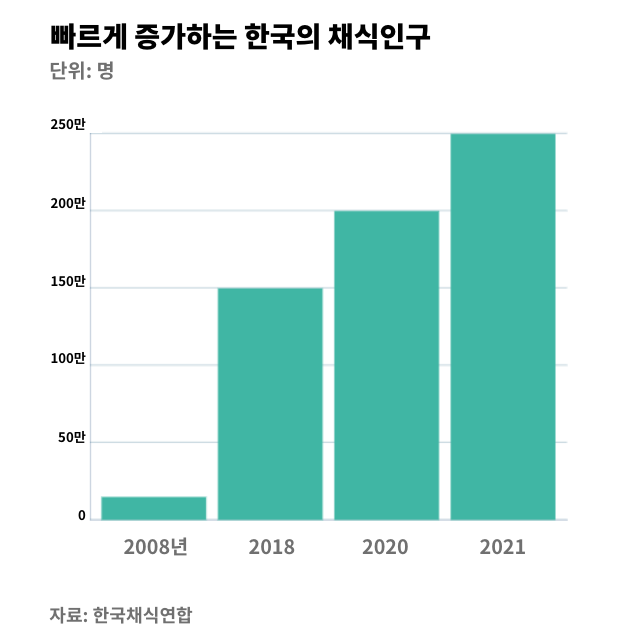

2021년 7월 A 일보에서 발행한 기사에 들어간 데이터 시각화입니다. 한국의 채식 인구를 나타낸 차트인데요, 한번 자세히 살펴보세요. 어딘가 이상해 보이진 않나요? 저는 두 가지 부분이 이상하다고 느꼈어요. 첫 번째는 X축에 나타나는 연도별 간격이 일정하지 않은 점, 두 번째는 추정 데이터를 사용한 점이에요.
이 데이터 시각화에서는 2008년, 2018년, 2020년, 2021년을 제시하고 있습니다. 2008년과 2018년은 10년 차이, 2018년과 2020년 사이는 2년 차이, 2020년과 2021년 사이는 1년 차이로 각 막대가 의미하는 연도의 기간이 다르죠.
얼핏보면 막대의 간격을 시간의 간격으로 인지할 수 있어서 가능하다면 일정한 시간 간격의 데이터를 활용할 필요가 있습니다. 1년 단위 또는 2년 단위처럼요. 이렇게 나열되어 있으면 데이터를 잘못 해석할 여지가 있어 지양해야 합니다. 원활한 커뮤니케이션에 방해가 되기 때문이죠. 데이터가 존재하지 않는 경우 X축의 이름을 조금 더 뚜렷해 보이도록 디자인 하는 것도 방법입니다.
두 번째는 데이터의 문제입니다. 채식 인구가 50만 명씩 일정하게 늘어나는 것이 이상해서 원본 데이터를 확인해보고 싶었어요. 출처에 표기된 한국채식연합 홈페이지에 들어가 데이터를 찾아보았는데요, 데이터를 발견할 수는 없었습니다.
대신 질문답변 게시판에서 “국내 채식인구에 대한 공식적인 통계자료가 없습니다. 한국채식연합은 국내 채식인구를 3~4%, 즉 150~200만 명으로 추정하고 있습니다. 채식 쇼핑몰 추이, 카페, 식당, SNS, 자체 길거리 설문조사 등 종합적인 판단을 통해 추정하고 있습니다”라는 답변을 확인할 수 있었습니다. 추정치 데이터로 만든 시각화였던 거죠.
보통 데이터를 제공할 때는 조사대상의 범위, 지역, 규모 등을 포함한 해당 기관의 통계산출 방법을 안내합니다. 데이터의 신뢰도를 높이기 위해서예요. 그래서 ‘이렇게 두루뭉술한 데이터를 굳이 시각화까지 해서 보여주어야 할까?’하는 의문이 들었답니다. 일반적으로 기사에서 시각화를 활용하는 이유는 데이터의 의미를 강조하기 위함이기 때문이에요.
이에 대해 어떻게 생각할지 팀원들과 의견을 나누어 봤는데요, 팀원들도 비슷한 생각을 하고 있더라고요.
– 이런 추정치는 텍스트로만 설명할 수 있었을 텐데, 굳이 차트로 만들어서 강조하는 게 의미 있을까요?
– 그럼에도 불구하고 시각화로 보여주고 싶다고 하면 추정치라는 내용을 명시해줘야 하지 않을까요? 추정치는 신뢰도가 떨어지니까요.
– 데이터 시각화는 데이터를 빨리 인지하게 하고 싶어서 사용하는 건데, 이미지 안에 설명이 들어가는 게 도움이 될까요? 지저분해보일 거 같은데요?
와 같은 의견이 나왔어요. 그러니까 두루뭉술한 추정치 데이터를 가지고 시각화하는 것은 지양해야 하지 않을까요? 여러분은 어떻게 생각하세요?

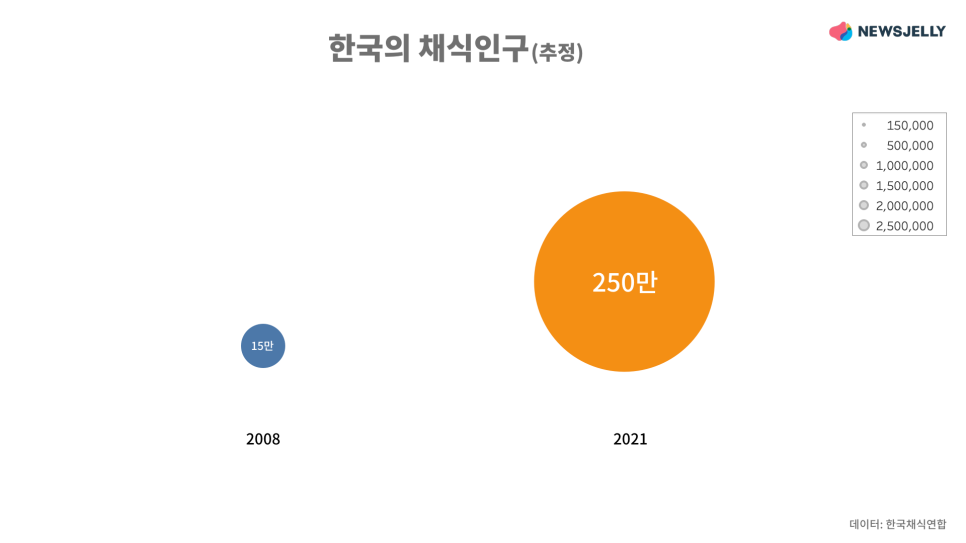
그래도 데이터 시각화로 보여주고 싶다면! 저는 이렇게 표현해보았습니다. 추정치니까 중간에 2018, 2020년 데이터는 중요하지 않다고 생각했어요. 그래서 원의 크기를 달리하여 2008년 대비 2021년 현재 채식 인구가 이만큼 늘어났다는 것을 직관적으로 보여주려고 했답니다. 여러분이라면 어떤 데이터 시각화 유형을 사용하시겠어요?
데이터 시각화의 첫 번째는 정보전달의 효율성!
지금까지 기사에 삽입된 막대차트 사례를 통해 잘못된 점이 무엇인지 알아보고, 올바른 데이터 시각화 차트를 제작해보았습니다. 앞서 언급했던 것처럼 시각화를 하는 사람마다 스타일이 조금씩 달라질 순 있지만 정확한 데이터의 의미를 전달하기 위해 지켜야 하는 요소들을 적용하여 재구성했음을 다시 한번 알려드립니다.
데이터 시각화는 데이터의 의미나 분석 결과를 사용자가 쉽게 이해할 수 있도록 하는 것이 가장 중요합니다. 예쁘게 만드는 것도 좋지만, 정보전달의 효율성을 고려해야 한다는 점! 항상 이 사실을 기억하고 또 기억해야 합니다. 의미를 효과적으로 전달하기 위해서는 형태와 기능, 두 가지가 조화를 이루어야 하기 때문입니다.
뉴스젤리 브랜드팀은 앞으로도 꾸준히 좋은, 정확한 시각화가 무엇인지를 이야기하는 ‘데이터 시각화의 재구성’ 콘텐츠를 선보일 예정입니다. 잘못된 데이터 시각화 사례를 찾아 어떤 시각화가 좋은 시각화인지 팀에서 이야기하고 재구성해보며 그 이야기를 여러분에게 전하고자 합니다. 다양한 차트를 보여드릴테니 많은 기대 부탁드려요!
데이터와 데이터 시각화에 관해 궁금한 사항이 있거나, 잘못된 시각화 사례를 발견하셨다면 언제든 뉴스젤리에게 알려주세요. 여러분의 적극적인 피드백을 기다리고 있겠습니다! 다음 콘텐츠에서 또 만나요! / Editor. 귤젤리
* 참고
– 클라우스 윌케『데이터 시각화 교과서』책만
– 후지 토시쿠니, 와타나베 료이치『데이터 시각화 입문』로드북
– 강원양, 임준원, 최현욱, 뉴스젤리『데이터가 한눈에 보이는 시각화』위키북스


