모델 성능 향상 및 목적에 맞는 분석모델 찾기

들어가며
현대 조직에서 인재를 찾고 유지하는 것은 조직의 성장과 발전에 있어 중요한 요소 중 하나입니다. 인사관리를 통해 직원의 퇴직을 사전에 예측하고 이를 방지하는 것은 조직의 지속 가능성과 성과 향상에 크게 기여합니다. 이런 과정에서 데이터를 기반으로 객관적이고 효과적인 인사 관리를 수행할 수 있습니다.
이번 ‘HR Analytics 끄적끄적’에서는 데이터 기반 인사관리의 중요성에 대해 알아보고자 합니다. 이를 위해 IBM의 HR Analytics Employee Attrition & Performance Data를 활용하고, 이를 R과 Chat GPT를 이용해 분석해 보겠습니다. 이 분석을 통해 직원 퇴직 예측 및 방지에 필요한 데이터를 도출하는 과정을 살펴보도록 하겠습니다.
이를 위해 먼저 머신러닝 알고리즘 중 하나인 랜덤포레스트를 활용하여 모델을 학습시키고, 그 결과를 Confusion Matrix를 이용하여 분석해 보고자 합니다. 그리고 이 모델의 성능을 올리기 위한 방법을 살펴보겠습니다. 랜덤포레스트 분석후에는 R과 Chat GPT를 활용한 직원 퇴직 요인 분석하기에서 활용하였던 로지스틱 회귀분석 분석 모델과 비교하여 어떤 모델이 퇴직 예측에 더 적합한 모델인지에 대해서 비교 분석해 보고자 합니다.
직원 퇴직과 관련한 정확도 높은 분석 모델을 도입함으로써 조직은 직원 퇴직을 미리 예측하고 이를 방지하기 위한 효과적인 인사관리 전략을 수립할 수 있습니다. 적절한 인사 관리는 조직의 지속성을 위해 매우 중요한 요소입니다. 이 글을 통해 데이터 분석이 HR 영역에서 어떻게 활용될 수 있는지, 그리고 이를 통해 어떤 가치를 창출할 수 있는지에 대해 고민해 보는 기회가 되었으면 좋겠습니다.
1. IBM HR Analytics Employee Attrition & Performance Data
1) IBM HR Analytics Employee Attrition & Performance Data란?
IBM HR Analytics Employee Attrition & Performance Data는 IBM의 HR부서에서 직원의 이직률 및 성과를 분석하기 위해 자주 사용되며 ‘HR Analytics 끄적끄적’ R과 Chat GPT를 활용한 직원 퇴직 요인 분석하기, R과 Chat GPT를 활용한 HR Data 시각화 편에서도 활용한 적이 있는 데이터 셋입니다. 이 데이터셋은 직원의 개인정보(나이, 성별, 교육 수준 등), 직장 내 경험(직무 만족도, 월급, 초과근무 여부 등), 그리고 이직 여부 등의 정보를 포함하고 있습니다. 이런 정보들은 인사관리와 관련된 다양한 분석과 연구에 주로 활용됩니다. 데이터셋 분석을 통해 다양한 조직들은 직원 이직률을 예측하거나 성과 향상 전략을 모색하는데 활용할 수 있습니다. 먼저 이 데이터 셋의 분석을 위해 해당 웹사이트로 이동해서 IBM HR Analytics Employee Attrition & Performance Data를 다운로드합니다.
그다음에 이 파일을 C드라이브 내의 Rdata 폴더에 저장합니다. 이후, R 스튜디오에서 이 폴더를 기본 디렉터리로 설정해 줍니다. 기본 디렉터리를 설정하는 방법은 아래와 같습니다.
| setwd(“c:/Rdata”) |
2) IBM HR Analytics Employee Attrition & Performance Data의 구성
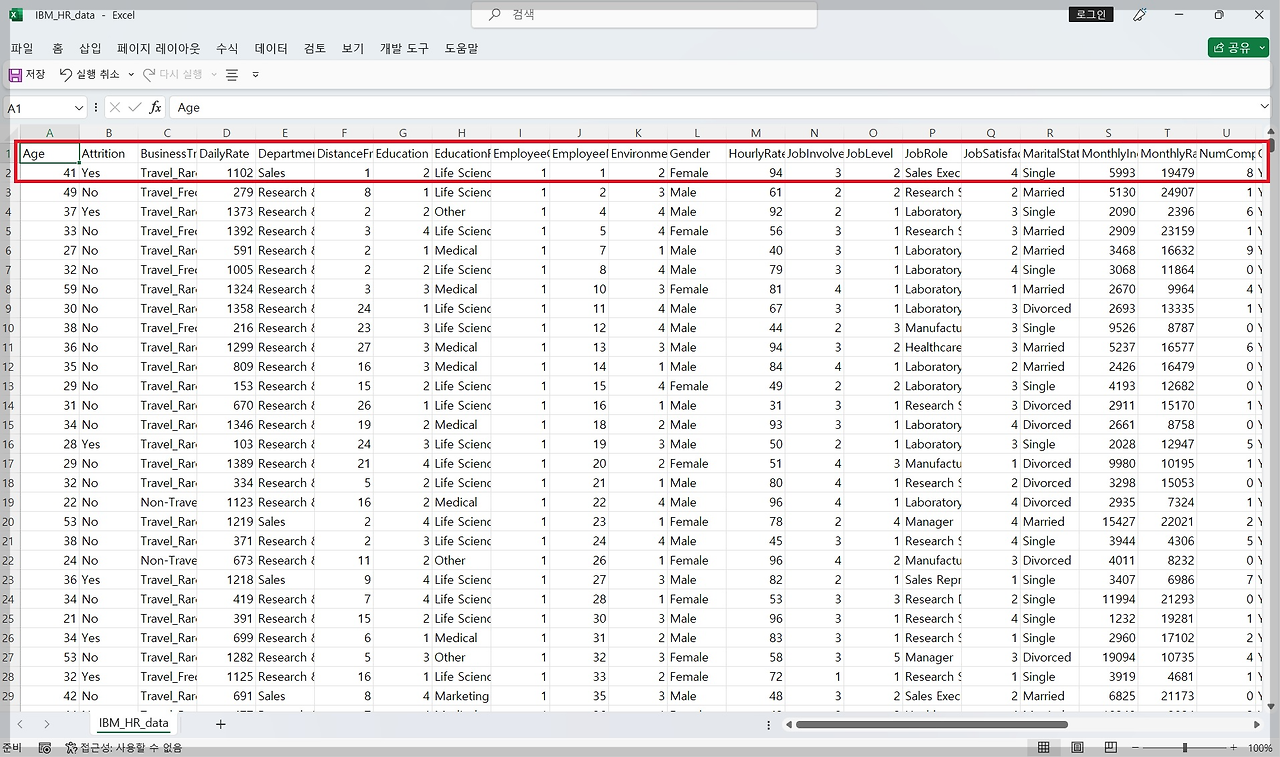
IBM HR Analytics Employee Attrition & Performance Data는 다양한 변수를 포함하고 있습니다. 이 중에는 나이, 성별, 학력 수준, 전공 분야, 월간 수입, 초과근무 여부, 직원의 이직 여부, 직원의 성과 평가 등급 등 총 35개 변수를 포함하고 있어 직원들의 이직률 예측, 성과 향상을 위한 요인 탐색 등의 분석을 실시할 수 있습니다. 또한 각 변수들은 서로 다른 타입으로 이루어져 있어 연속형 변수와 범주형 변수에 대한 다양한 분석 방법을 적용해 볼 수 있습니다. 35개 변수의 세부적인 내용은 아래 표와 같습니다.
| Age: 직원의 연령 Attrition: 직원이 회사를 떠났는지에 대한 여부 (예 or 아니오) BusinessTravel: 출장 빈도 (출장 없음, 가끔 출장, 자주 출장) DailyRate: 하루 동안 받는 급여 Department: 직원이 속한 부서 (Research & Development, Sales, Human Resources) DistanceFromHome: 직원의 주거지에서 사무실까지의 거리 Education: 직원 최종 학력 (1: Below College, 2: College, 3: Bachelor, 4: Master, 5: Doctor) EducationField: 직원의 전공 EmployeeCount: 직원수 (모든값 1로 동일) EmployeeNumber: 직원을 식별하는 고유 번호 EnvironmentSatisfaction: 직원이 업무환경에 만족하는 정도 (1: 낮음, 2: 중간, 3: 높음, 4: 매우 높음) Gender: 직원의 성별 (남성, 여성) HourlyRate: 직원의 시간당 받는 급여 JobInvolvement: 직원 직무몰입 (1: 낮음, 2: 중간, 3: 높음, 4: 매우 높음) JobLevel: 직원 직급 JobRole: 직원이 수행하는 업무 JobSatisfaction: 직원이 자신의 직무에 만족하는 정도 (1: 낮음, 2: 중간, 3: 높음, 4: 매우 높음) MaritalStatus: 직원의 결혼 여부 (미혼, 기혼, 이혼) MonthlyIncome: 직원 월급여 MonthlyRate: 직원이 한 달 동안 받는 총 급여 NumCompaniesWorked: 직원이 근무한 과거 회사의 수 Over18: 직원 18세 이상 여부 (모든 값이 Y) OverTime: 직원이 정규 근무시간 외에도 근무하는지 여부 (예, 아니오) PercentSalaryHike: 직원의 급여가 얼마나 인상되었는지에 대한 비율 PerformanceRating: 직원의 성과에 대한 평가 등급 (1: 낮음, 2: 좋음, 3: 우수, 4: 탁월) RelationshipSatisfaction: 직원의 동료관계 만족도 (1: 낮음, 2: 중간, 3: 높음, 4: 매우 높음) StandardHours: 직원 표준 근무시간 (모든 값이 80으로 동일) StockOptionLevel: 직원이 보유한 주식 옵션의 수준 (0, 1, 2, 3) TotalWorkingYears: 직원의 전체 근무 기간 TrainingTimesLastYear: 지난해 직원이 받은 훈련의 횟수 WorkLifeBalance: 직원의 일과 삶의 균형 (1: 나쁨, 2: 좋음, 3: 더 좋음, 4: 최고) YearsAtCompany: 직원이 현재 회사에서 근무한 기간 YearsInCurrentRole: 직원이 현재 역할을 수행한 기간 YearsSinceLastPromotion: 직원이 마지막으로 승진한 후 지난 기간 YearsWithCurrManager: 직원이 현재의 상사와 근무한 기간 출처: HRKIM. 2023. “R과 Chat GPT를 활용한 직원 퇴직 요인 분석하기”. HRKIM(브런치). 2023년 7월 2일 접속. https://brunch.co.kr/@publichr/37. |
2. R과 Chat GPT를 사용한 IBM 직원 퇴사자 예
IBM의 HR Analytics Employee Attrition & Performance Data를 활용하여 퇴직 가능성이 높은 직원을 예측하는 방법으로, 랜덤 포레스트 알고리즘을 선택하였습니다. 기존 R과 Chat GPT를 활용한 직원 퇴직 요인 분석하기에서는 로지스틱 회귀분석을 통해 퇴사자 예측을 진행한 바 있는데요. 랜덤포레스트는 로지스틱 회귀분석과 더불어 퇴사자를 예측하는 데 적합한 분석 기법입니다.
이번 챕터의 목표는 직원의 개인정보와 특성을 기반으로 퇴직 가능성을 정확하게 예측하는 모델을 찾는 것입니다. 이를 통해 조직은 개별 직원에 대한 효과적인 인사관리 전략을 개발하고 실행할 수 있습니다. 이러한 접근은 조직의 효율성 향상, 직원의 만족도 증대, 그리고 장기적으로는 조직의 성과 향상에 기여할 것입니다.
1) Random Forest 정의
Random Forest는 머신러닝의 대표적인 알고리즘 중 하나로, 여러 개의 의사결정나무(Decision Trees)를 생성하고 그들의 예측 결과를 종합하는 방식으로 동작합니다. 이를 통해 개별 트리의 예측 오차를 상쇄하고 모델의 예측 성능을 향상시킵니다.
랜덤 포레스트는 각각의 트리가 서로 독립적으로 학습을 수행하기 때문에, 알고리즘의 병렬 처리가 가능하다는 장점이 있습니다. 이는 큰 데이터셋에 대해서도 빠른 학습 시간을 보장해 줍니다. 또한, 랜덤 포레스트는 중요 변수 선택, 이상치의 영향 최소화, 결측치 처리 등의 다양한 장점을 가지고 있습니다.
2) Random Forest 분석 R 코딩
이제 실제로 랜덤 포레스트 분석 모델을 위한 R코드를 작성해 보겠습니다. 이를 위해 Chat GPT의 도움을 받겠습니다. Chat GPT의 도움을 받기 위해 Data를 입력하고자 합니다. R과 Chat GPT를 활용한 HR Data 시각화에서도 언급드렸던 바와 같이 인사정보 Data는 매우 예민한 정보이기 때문에 이를 Chat GPT에 직접 전달하는 것은 부담스럽습니다. 따라서 인사정보 데이터의 형식을 Chat GPT가 인지할 수 있도록 열제목과 1행 정보만 제공(1행 정보 제공도 부담스러울 경우 데이터 내용을 가상으로 전달 가능 합니다.)하고 데이터의 형식을 추가로 설명해 주었습니다.

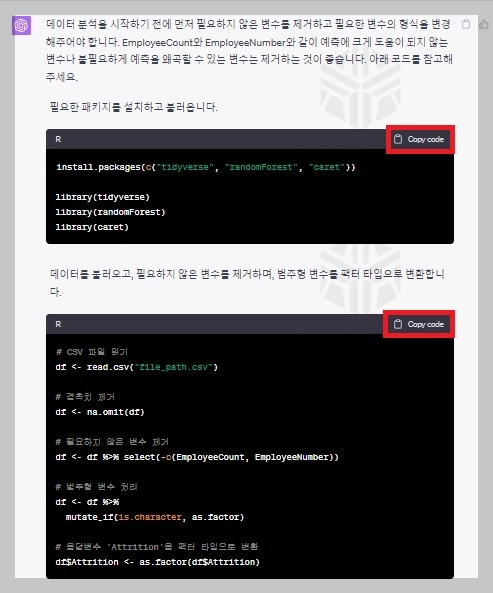


Data 양식을 Chat GPT에게 설명한 후 Random Forest 분석을 위한 R코드를 요청한 결과 Chat GPT는 아래 화면과 같이 R코드를 작성해 주었습니다. 해당 R코드의 내용을 설명하자면 다음과 같습니다.
먼저, ‘tidyverse’, ‘randomForest’, ‘caret’ 패키지를 설치하고 불러옵니다. 그리고 분석하고자하는 CSV 파일을 불러옵니다. ‘na.omit’ 함수를 사용하여 불러온 데이터에서 결측값을 제거하고 분석에 필요하지 않은 ‘EmployeeCount’와 ‘EmployeeNumber’ 변수를 ‘select’ 함수를 사용하여 제거하였습니다. 그 후에는 ‘mutate_if’ 함수를 이용해 문자열로 되어있는 모든 변수를 범주형 변수인 팩터로 변환하였습니다. 더불어 응답변수 ‘Attrition’도 팩터 타입으로 변환하였습니다.
다음으로 랜덤 시드를 설정한 후, ‘createDataPartition’ 함수를 사용하여 데이터의 80%를 학습용으로, 나머지 20%를 테스트용으로 분할하였습니다. 그 이후로는 ‘randomForest’ 함수를 사용하여 랜덤포레스트 모델을 학습시켰으며 트리의 개수는 500개로 설정하였습니다. 마지막으로, ‘confusionMatrix’ 함수를 사용하여 예측된 값과 실제 테스트 데이터의 ‘Attrition’ 값 간의 혼동 행렬을 생성하고, 모델의 성능을 평가하였습니다.
위와 같은 R 코드를 R Studio에서 실행하면, Random Forest의 분석 결과를 얻을 수 있습니다. 하지만 이 결과도 전문적인 배경지식이 없으면 이해하기 어렵습니다. 이때 Chat GPT를 추가로 활용하면, 분석 결과의 이해를 돕는 해석을 제공받을 수 있습니다.
3) Chat GPT를 활용한 Random Forest 분석결과의 해석
Chat GPT는 Random Forest 분석결과를 해석하는 데에 큰 도움을 줍니다. Chat GPT는 일반 사용자가 이해하기 쉽도록 해당 분석결과를 간결하고 명확한 문장으로 설명해줍니다. Chat GPT는 분석결과의 중요한 부분과 모델 성능을 이용자가 이해하기 쉽도록 설명해 줍니다.


위와 같이 Chat GPT에게 Confusion Matrix 분석결과의 해석을 요청한 결과 Chat GPT는 Confusion Matrix의 분석결과에 대해서 이해하기 쉽게 설명해 줍니다.
4) Random Forest 분석 모델의 성능 높이기
분석 결과에서 다른 지표에 비해 특이도(Specificity)가 낮은 것을 발견했습니다. 이에 따라 특이도를 포함한 분석 모델의 성능을 향상시키기 위한 방법에 대해 Chat GPT에게 추가 문의를 하였습니다. 해당 질문을 통해 Chat GPT가 추천한 방법 중 오버샘플링과 하이퍼파라미터 조정을 포함한 Random Forest R 코드를 다시 요청했습니다.
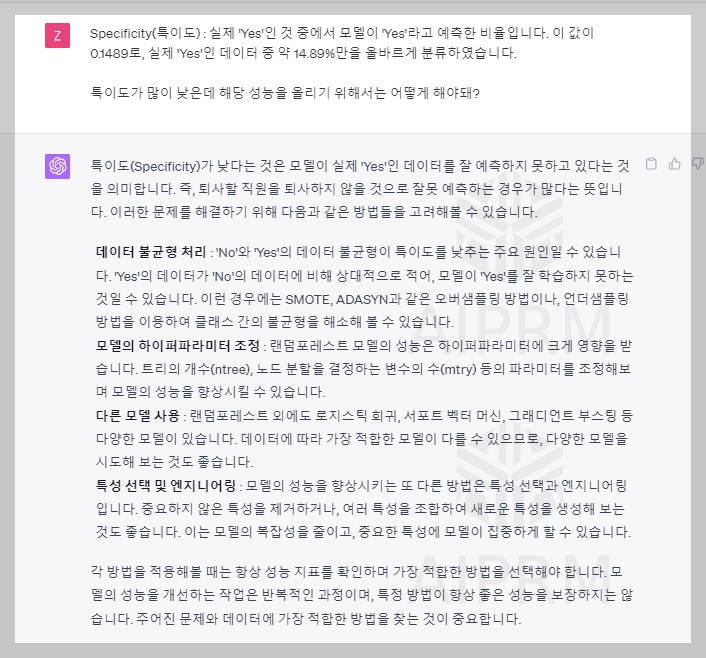





오버샘플링과 하이파라미터조정을 진행한 후 분석을 다시 실시하여 모델 개선 전과 모델 개선 후의 분석결과를 Chat GPT에게 제시하고 모델 성능이 증가하였는지 질문하였습니다. Chat GPT는 개선 전과 개선 후 모델 성능을 비교한 결과 정확도는 약간 감소하였지만, Kappa 값이 증가하였으며 특이도가 상당히 증가하여 전체적으로 모델 성능이 개선되었다고 답변하였습니다. 하지만 이직할 직원을 예측하는 성능이 여전히 낮기 때문에 추가적인 샘플링 기법이나 다름 모델 방법을 통해 성능을 더욱 향상시킬 수 있다고 언급하였습니다.
5) Random Forest 분석 모델과 Logistic Regression 분석 모델 성능 비교하기
기존 R과 Chat GPT를 활용한 직원 퇴직 요인 분석하기에서는 로지스틱 회귀분석을 통해서 퇴직자 예측 및 영향요인을 분석한 바가 있습니다. 이번 챕터에서 사용한 랜덤포레스트 분석 모델과 기존 사용했던 로지스틱 회귀분석 모델 중 어떠한 모델이 퇴직자를 예측하는데 더 성능이 뛰어난지 비교해 보도록 하겠습니다. 랜덤포레스트 분석모델과 동일하게 Chat GPT에게 로지스틱 회귀분석 모델의 R 코드를 요청했고, 받은 코드를 통해 로지스틱 회귀분석을 수행했습니다(로지스틱 회귀분석을 이전에 다룬적이 있으므로 해당 과정은 생략). 아래의 화면은 로지스틱 회귀분석과 랜덤 포레스트 분석의 결과를 Chat GPT에게 제시하고, 두 모델 간의 성능을 비교해달라고 요청한 내용입니다.


랜덤포레스트 분석모델과 로지스틱 회귀분석 분석모델을 비교한 결과 각 모델은 서로 다른 장점을 가지고 있습니다. 단순히 이직할 직원을 더 정확하게 예측하는 것이 모델의 목표라면 랜덤포레스트 분석모델보다는 로직스틱 회귀분석 모델을 선택하는 것이 더 적합합니다. 하지만 전체적인 성능(정확도 및 민감도)은 랜덤포레스트가 높은 것으로 나타났습니다. 우측 상단 화면에서 Chat GPT가 설명하고 있는 바와 같이 이직하지 않을 직원을 잘 예측하는 것이 목표라면 랜덤포레스트 모델을 사용하는 것이 효과적이며, 이직할 직원을 잘 예측하는 것이 목표라면 로지스틱 회귀분석을 선택하는 것이 효과적입니다.
나가며
이번 ‘HR Analytics 끄적끄적’ 챕터에서는 IBM HR Analytics Employee Attrition & Performance Data를 통해 퇴직직원을 예측하기 위해 머신러닝 알고리즘인 랜덤 포레스트를 사용하였으며, 랜덤포레스트 분석 후에는 오버샘플링과 하이퍼파라미터 조정 등을 통해 모델의 성능을 개선하는 방법을 살펴보았습니다. 또한 기존 R과 Chat GPT를 활용한 직원 퇴직 요인 분석하기에서 사용한 로지스틱 회귀분석 모델과 비교하여 어떠한 모델이 퇴직자를 예측하는데 더 적합한지도 비교 분석을 해보았습니다.
데이터와 기술의 발전은 인사관리에 접근하는 방식을 변화시키고 있습니다. 현재 조직의 HR 팀은 데이터 분석을 활용하여 직원들을 보다 체계적이고 과학적으로 관리할 수 있게 되었습니다. 이는 조직의 생산성 향상에 긍정적인 역할을 합니다. 그러나 HR Analytics 분석결과를 활용시에 간과해서는 안 될 중요한 부분이 있습니다. HR Analytics 분석 결과를 참고하여 다양한 인사관리를 수행할 시에 리더십, 조직문화 등을 고려한 인사관리가 필요합니다. 이러한 요소들이 함께 고려할시에 효과적인 데이터 기반 인사관리가 가능해 집니다.
이러한 점을 잊지 않고, 앞으로 HR Analytics를 활용하여 조직의 성장과 직원들의 행복을 추구하는 모든 분들이 좀 더 성공적인 결과를 얻을 수 있기를 기대합니다. 마지막으로, ‘데이터는 새로운 원유다’라는 표현이 최근 사회에서 빈번히 강조되고 있습니다. 이런 원유를 적절히 활용하여 조직의 미래를 예측하고, 방향성을 결정하는 데 중요한 역할을 하기를 희망합니다. 이 글이 그러한 과정에서 도움이 되길 바라며, 여러분의 여정에 조금이나마 도움이 되길 바랍니다.
Reference
- HRKIM. 2023. “R과 Chat GPT를 활용한 직원 퇴직 요인 분석하기”. HRKIM(브런치). 2023년 7월 2일 접속. https://brunch.co.kr/@publichr/37.
- HRKIM. 2023. “R과 Chat GPT를 활용한 HR Data 시각화”. HRKIM(브런치). 2023년 7월 2일 접속. https://brunch.co.kr/@publichr/48.
김창일 님이 브런치에 게재한 글을 편집한 뒤 모비인사이드에서 한 번 더 소개합니다.
![]()
![]()


