
기획을 시작하고 나서 처음에 가장 많이 연습한 것 중 하나는 ‘이슈 트리’ 혹은 ‘로직 트리’라 부르는 것을 그리는 것이었습니다. 이슈 트리는 처음 접근하는 문제를 쉽게 모델로 만들고 가장 중요한 것이 무엇인지 찾는데 역할이 있습니다. 가장 큰 과제를 하나 두고 이걸 구성하는 것으로 쪼개어 보는 것이죠. 이 과정에서 시장을 전혀 모르거나 초심에서 봐야 하는 것이라면 중복과 누락이 없는 방식으로 물리적으로 나누기도 합니다. 물론 이럴 필요가 없을 정도로 이미 몇 가지 키 팩터에 대해 생각하고 있는 가설이 있다면 가설을 중심으로 이슈 트리를 그리기도 합니다.

데이터가 어디에 있는지를 기준으로 한 단계 뻗어나가는 이슈 트리는 누락과 중복을 막습니다. 하지만 분류 문제로 구분 바깥에 있는 핵심이 눈에 보이지 않는 단점이 있죠.
윗사람 설명에 최적화되어버린 도구
이슈 트리는 과제 분야를 모르는 사람에게 한눈에 요소요소를 알기 쉽게 만들어 주는 장점이 있습니다. 만약 ‘우리 회사에 어떤 데이터를 핵심 자산으로 관리해야 하는지’를 이슈 트리를 그려 해결하고자 할 때 위에 예시로 든 도표와 같이 드리면 논리적으로는 문제가 없지만 이미 데이터 존재 위치가 핵심 자산을 구분하는 하나의 기준으로 암묵적으로 자리잡기에 이 기준이 아니라면 아무리 이걸 더 세부적으로 분해해 봐도 적합한 결론에 도달하지 못하는 한계가 있습니다.
하지만 데이터라는 것을 정확히 모르는 윗사람은 한눈에 이게 어떻게 실무에 존재하는지 보여주는 것 같은 착시를 만들게 되죠. 정말 중요한 문제가 뭐라고 말하면 무엇이 있는지 배경 지식이 부족한 임원에게 신뢰를 주지 못할 수 있지만 이렇게 이슈 트리를 그려서 꽉 차고 논리적으로 위아래가 척척 맞는 도식을 가져다주면 마치 다 파악했다고 느끼게 만들어 준다는 것이죠. 그저 학습을 위한 백과사전은 될 수 있지만 정말 문제에 도달하는 것을 말하지 못하게 만들 수 있다는 것입니다.
무엇을 기준으로 나누어야 정답을 찾을 수 있는가
그래서 이슈 트리는 무엇을 기준으로 나눌 것인가가 중요합니다. 이슈 트리와 비슷한 모양 중 ‘의사 결정 나무(Decision Tree)’가 있습니다. 분류에 활용되는 고전적인 알고리즘인데 머신러닝에 여러모로 기초가 되는 콘셉트입니다. 의사결정 나무가 사랑받는 이유 중 하나는 사람이 알아듣기 쉽게 설명할 수 있다는 점이 있습니다. 처음 나무 가지를 분기해서 나갈 때 데이터 중에서 가장 중요한 구분 기준을 컴퓨터가 찾아서 그걸로 분리 기준을 만들어 주기 때문입니다.
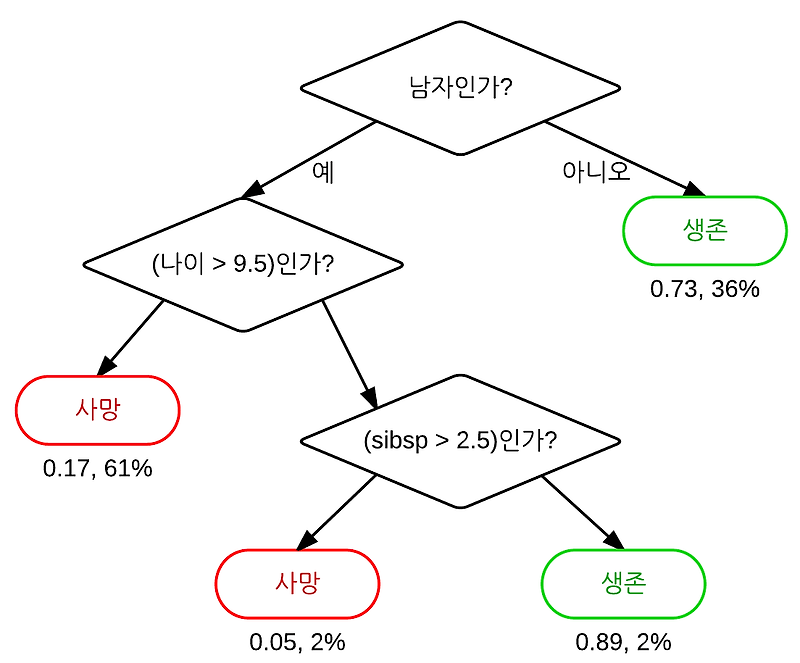
위의 뻗어나가는 모양의 도식은 의사결정 나무의 간단한 예시입니다. 타이타닉호에 생존하는 사람은 누구인지 분석한 결과 예시입니다. 가장 처음 보이는 ‘남자인가?’인가 에서 타이타닉호에 탑승한 사람 중 생존 조건이 크게 좌우되는 것으로 나타납니다. 나이가 몇 살 이상이고 함께 탑승한 배우자와 자녀를 더한 수를 나타내는 ‘sibsp’도 생존을 좌우하는 중요한 기준(변수)이 되지만 남자인지 여자인지가 사실 가장 큰 영향을 미치는 것이죠. 사족으로 의사결정 나무가 이슈 트리와 다른 점은 의사결정 나무에서 ‘남자인가?’ 같은 구분 기준의 답이 이분법이 아닌 경우 아래 세부적인 어딘가에서 다시 나올 수도 있지만 이슈 트리는 트리 하이어라키에 중복해서 나올 수 없는 점 정도입니다.
타이타닉에 탄 사람을 1등 칸, 2등 칸, 3등 칸으로 먼저 나눌 수도 영국인, 미국인, 그 외 국적으로 나눌 수도 있습니다. 하지만 이런 구분으로 위에서 나누어 버리면 아래에 더 세부적으로 나누어도 문제의 뿌리에 도달하지 못하는 일이 생기는 것이죠. 최근 기획, 전략 분야에서 머신러닝을 위시한 데이터 분석이 함께 각광받는 이유이기도 합니다. 과거 케이스 스터디, 논리적 오류 없음이 정답을 찾는 빠른 답이 되지 못하는 것이죠.
여전히 필요한 지도(map)로써의 이슈 트리
이런 비판들을 보면 이슈 트리는 마치 과거의 것 같습니다. 하지만 여전히 의사결정 나무를 돌릴 만큼 데이터는 충분치 않고 결과에 영향을 주는 수많은 변수들은 현장에서 모두 비슷해 보입니다. 그리고 여전히 공부시켜드려야 할 윗사람도 존재하고 안 만든다고 말하면서 PPT만 아닌, 매일 만드는 보고서도 있습니다. 이슈 트리는 마인드맵이든 어떤 모양으로 머릿속에서 혹은 보고서 위에서 그려지고 있습니다.
여기에 제가 생각하는 이슈 트리의 최대 미덕이 있습니다. 해 보고 아니면 피드백을 할 수 있는 것이죠. 머신 러닝에서 하이퍼 파라미터의 케이스를 찾아 지우는 일을 하는 것처럼 말이죠.

위에 복잡한 이슈 트리를 보시죠. 회사에서 마치 실제 썼던 것 같은 수준의 디테일을 갖고 있는 이슈 트리 사례군요. 어떻게 하면 회사의 이익률을 올릴 수 있을지 논리적으로 구분했습니다. 여기서는 이익이라는 항목을 재무적으로 중복과 누락 없이 구분해서 먼저 매출을 늘리거나 비용을 줄이는 것으로 나누었네요. 처음 분기한 두 내용, 매출과 비용은 다시 그것들을 극대화시키는 재무 공식을 구성하는 하위 요소들로 나누어집니다. 마지막 레벨, 의사결정 나무라면 나뭇잎으로 불릴만한 가장 아래 디테일에는 신규 고객 확보를 위해 미디어에 프로모션 예산을 쓰는 것이나 제조 원가를 줄이기 위한 대체재를 찾는 방안도 있습니다.
이슈 트리를 그리는 이유는 이 중에서 한 가지 집중할 과제 제목을 찾는 것이죠. 이 복잡한 디테일 중에서 우리 조직이 가장 큰 문제라고 생각하는 것을 찾고 그것을 실행하고 결과를 보는 것이죠. 재무제표로 구분된 위 이슈 트리에서는 최근 재무제표에 영향을 미친 항목을 중심으로 하거나 비슷한 구조를 하긴 회사와 비교를 통해 취약점을 찾아내어 실제 할 것을 정할 수도 있습니다. 물론 처음 말씀드렸듯이 재무제표로 나누는 순간 보이지 않는 것이 발생한다는 한계점은 논외로 하죠.
대부분은 여기까지 합니다. 이슈 트리 그리고 실행하는 것까지 말이죠. 그리고 안되면 이슈 트리 그린 노력이 무색하게 모두 백지화시킵니다. 다른 방법들이 이슈 트리 하단에 나와 있는데 하나 잡은 액션으로 단정 짓고 그거 하고 아니면 사업 전체를 접어 버리거나 엉뚱한 자원 투여를 해서 문제를 악화시키는 것이죠. 이슈 트리를 이렇게 자세히 나눈 이유가 저 나뭇잎이 아니면 다른 가지에서 뻗어 나온 다른 나뭇잎이 정말 문제인지 피드백해서 Try&Error 방식으로 학습하는 조직을 만들어 답을 찾는 것은 모른 채 말이죠.
Try&Error
사업이 의사결정 나무 돌리듯 무엇 무엇이 가장 높은 확률로 사업을 살릴 액션이니 이것부터 하라고 컴퓨터가 이미 한 일의 패턴을 보고 알려준다면 얼마나 좋을까요? 하지만 그런 일은 드뭅니다. 넣지 않는 데이터, 넣을 수 없는 데이터가 많은 사업은 이슈 트리의 액션을 컴퓨터가 아닌 사람을 통해 학습하게 만듭니다.
전체 피벗을 하기 전까지 다양한 액션을 빨리 해 보고 아니면 다시 이슈 트리로 돌아와 다른 것을 검증해 보는 것입니다. 그 쓸모를 위해 이슈 트리는 많은 고민과 노력으로 만듭니다. 만약 서비스를 개발한다고 합시다. 현재 일부 솔루션만 있는 앱에 커뮤니티 기능도 넣고 서로 평가하는 기능도 넣습니다. 하다 보니 커머스 기능도 연결시켰죠. 그런데 어느 순간 트래픽이 떨어지고 전체적인 실적이 둔화됩니다. 문제가 어디에 있을까요? 이슈 트리를 퀵하게 그려봅니다. 우리가 더한 기능들을 분해하고 로그 데이터를 분석합니다. 이 과정을 통해 이슈 트리를 만들 수 있습니다. 어느 부분을 실험해서 바꿀지 우선순위를 정하고 합니다. 실험군과 대조군을 테스트해서 원하는 결과가 나오지 않으면 다시 그렸던 이슈 트리의 다른 부분을 바꾸고 테스트합니다.
이 자연스러운 흐름이 안 되는 곳도 있습니다. 하나 해보고 안되면 다른 서비스를 만들자고 합니다. 기존에 투입된 자원에서 다시 쓸 것도 없이 날려 버립니다. 유통이나 제조를 하는 브랜드라면 다른 상품군을 판매하자고 합니다. 기존에 잘 팔았던 것을 낡은 것이라고 그냥 정하고 다른 것을 팔아서 힙한 브랜드가 되자고 합니다. 이런 선택으로 발전된 사업은 나중에 피드백할 것도 남지 않습니다. 회사 내부에서 정치적으로 우회하고 싶은 모면하고 싶은 모습들이 모두를 힘들게 하는 것으로 남겠죠.
물론 답은 하나가 아니다
도구는 도구일 뿐입니다. 도구가 문제 해결 능력을 도와주기는 하지만 그 자체가 될 수는 없죠. 이슈 트리도 그렇습니다. 이슈를 나누면서 내려갈 때 ‘How’를 중심으로 내려갈지 ‘Why’를 중심으로 내려갈지 필요에 따라 정할 수 있습니다.
실무를 한 입장에서 이게 뭐 오랜 시간 붙잡고 있을 만한 내용도 아닌 것 같기도 합니다. 결국 그리는 사람의 비전의 크기와 구분을 하는 관점이 중요한 것이니 오래 붙잡는다고 갑자기 없던 눈이 생겨서 적확한 기준으로 트리를 그리기도 어렵습니다. 하지만 암묵지를 형식지로 만들고 나만 갖고 있는 것을 공유하는 형태로 바꾸고 로컬 파일을 클라우드로 바꾸는 것을 하는 이유처럼 기록하고 공유하고 피드백하면 우리는 과정 중에서 작은 실마리를 찾을 수 있습니다.
학습 데이터를 바꿔야 할지 알고리즘을 바꿔야 할지, 학습 데이터를 바꾼다면 기존 데이터에서 층화 추출을 하는 방식으로 비중을 조정하면서 갈지, 희소한 필드 값의 절대 값을 더 늘려야 할지 정해야 할 수도 있습니다. 알고리즘을 바꾼다면 알고리즘 자체를 바꿀 수도 있지만 하이퍼 파라미터를 수정하는 방법도 생각해 볼 수 있겠죠. 이 순간순간의 결정에 이슈 트리가 빠르고 남는 도구가 될 수 있을 것입니다.
PETER님이 브런치에 게재한 글을 편집한 뒤 모비인사이드에서 한 번 더 소개합니다.
![]()

의 시대는 마케터의 시대?")
